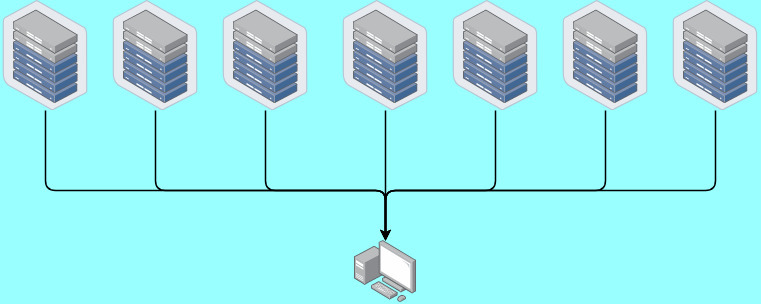
Private Information Retrieval
Research Project
Guides: Prof. Nikhil Karamchandani and Prof. Bikash Kumar DeyDuration: August 2021 - June 2022
In this project, we study the fundamental limits of a few variations of the canonical Private Information Retrieval (PIR) problem.
In the canonical setting, a user wishes to retrieve a randomly chosen file from a set of files from non-colluding databases, each of which has a copy of each file without giving away any information about the file being requested to the servers. In the real word, this scenario might arise when someone wants to download, say, a movie or a book, without letting any of the servers know which movie they want to watch.
One trivial method to do this is to download all of the movies available, but the download cost there is prohibitive. One therefore needs to request information cautiously and minimize the amount of information downloaded (considering that the files are large, the upload cost is minimal in comparison). In 2016, Sun and Jafar established the maximum capacity of PIR in this setting. However, there are various modifications of this problem that are yet to be analysed. We investigated the PIR capacity in a few such settings.